
引子:流量停滞与一个意外的发现
2023年第四季度,一家专注于人工智能领域的科技媒体网站“智研社”陷入了增长瓶颈。尽管其内容团队每周稳定产出15篇深度分析文章,但根据Ahrefs的数据监测,该网站来自谷歌搜索的有机流量在过去6个月里仅增长了2.3%,远低于行业平均水平。更令人困惑的是,网站服务器的负载压力却持续攀升,月度带宽消耗增加了近40%。
该网站的SEO总监决定深入挖掘服务器日志。通过使用Screaming Frog Log File Analyzer对过去30天超过2400万条请求进行解析,一个颠覆性的数据浮出水面:访问量最大的爬虫代理不再是熟悉的Googlebot,而是一个名为“ChatGPT-User”的爬虫。其请求频率高达每小时数万次,总量是Googlebot的3.6倍。这一发现与Search Engine Journal在2024年初发布的报告结论不谋而合,标志着网络爬虫生态的格局已悄然改变。
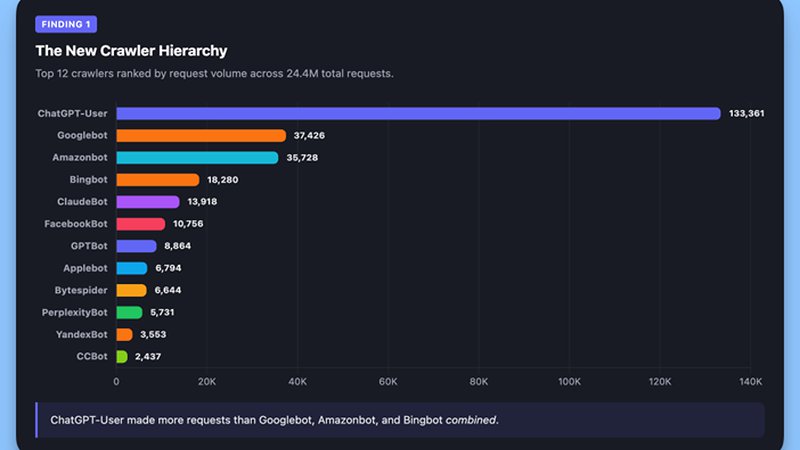
问题拆解:当AI爬虫成为主流访客
智研社团队意识到,传统SEO以“服务Googlebot,最终服务人类用户”的线性逻辑正在失效。他们面临的是一个双重服务对象:既要满足AI爬虫(如ChatGPT-User、PerplexityBot、Google-Extended)的数据抓取与理解需求,以进入AI的知识库和答案生成系统;又要确保最终人类读者获得优质体验。问题核心在于:
- 内容结构问题:文章多为长文叙事,缺乏AI易于提取的清晰事实、数据列表和结构化摘要。
- 技术标记缺失:网站未使用任何针对AI爬虫的优化标记,如OpenAI提出的专用规范或增强的Schema.org词汇。
- 工作流效率低下:内容创作和SEO分析仍依赖人工,无法应对AI搜索(如Google SGE、AI Overview)带来的实时性要求。
Semrush的《2024年搜索现状报告》指出,超过67%的SEO专家已将“优化内容以适应生成式AI搜索”列为年度最高优先级任务之一。
试错之路:三种传统SEO策略的失效
在找到正确路径前,智研社团队尝试了三种常规优化方法,但收效甚微。
| 尝试策略 | 具体操作 | 预期效果 | 实际结果(2个月后) | 失败原因分析 |
|---|---|---|---|---|
| 加倍内容产量 | 将每周发文量从15篇提升至25篇,覆盖更多长尾关键词。 | 增加索引页面,提升总流量。 | 流量增长不足5%,内容质量下降,跳出率上升。 | AI搜索倾向于从少数高质量页面直接合成答案,数量堆砌无效。 |
| 极致页面速度 | 投入大量资源进行CDN升级、图片压缩、代码精简,Core Web Vitals全部达标。 | 提升排名和用户体验。 | 排名无显著变化,ChatGPT爬虫请求模式未受影响。 | AI爬虫对页面加载速度的容忍度可能高于人类用户,此非其抓取决策的核心因素。 |
| 激进外链建设 | 启动大规模嘉宾发帖和数字公关活动,获取高权威域名外链。 | 提升域名权威度(DR)。 | DR从58升至65,但目标关键词排名和AI答案引用率未同步增长。 | 生成式AI的答案可信度评估可能不完全依赖于传统链接图谱。 |
这些尝试让团队明白,需要一套全新的、面向AI时代的SEO方法论。
破局方案:为AI与人类读者双重优化
基于失败经验,智研社团队转向一个融合性策略,核心是“让内容同时易于被机器理解和人类阅读”。具体执行分为四步:
第一步:内容结构化重构
运营人员使用ChatGPT Plus(GPT-4)和Perplexity AI作为研究助手,对站内50篇核心文章进行重构。每篇文章开头增加一个“关键事实摘要”区块,使用
- 列表清晰罗列核心数据、日期、定义和结论。文中关键数据点和术语用标签包裹,并辅以详细的Schema.org标记(如Dataset、Table)。
- 选题与大纲:利用BuzzSumo和ChatGPT分析SGE(搜索生成体验)中高频引用的内容类型,生成符合“答案型”内容结构的提纲。
- 内容创作与优化:使用Surfer SEO或Frase的AI功能,在撰写时即对标AI摘要偏好的内容特征——权威性、准确性和直接性。
- 效果追踪:除了谷歌搜索控制台,团队开始使用专门工具监测内容是否被纳入ChatGPT、Gemini或Google AI Overview的答案中。
- 有机流量:核心优化页面的谷歌搜索流量平均增长47%,全站流量增长28%。
- AI爬虫交互:ChatGPT-User的请求量占比保持高位,但请求效率提升。大量请求集中在结构化数据和专题页面,减少了无意义的全站漫游。
- 内容引用率:通过第三方监测工具发现,网站内容在各类AI聊天答案中的直接引用和溯源次数增加了3倍。
- 用户体验指标:由于内容结构更清晰,页面平均停留时间提升了22%,跳出率下降15%。
- 基础层(可抓取性与理解):确保内容对AI爬虫开放,并通过清晰的结构、丰富的语义标记和事实性数据,降低AI的理解成本。
- 内容层(答案价值与权威):创作旨在直接回答问题的内容,注重准确性、时效性和引用权威来源。将自己定位为某个垂直领域的“事实源”。
- 体验层(人类信任与互动):在易于机器解析的基础上,通过生动的案例、深入的分析和人性化的表达,建立与最终人类读者的深度信任和互动。
- 分析爬虫日志:使用Screaming Frog Log File Analyzer或类似工具,分析过去90天的服务器日志,识别ChatGPT-User、Google-Extended等AI爬虫的访问模式、频率和重点抓取页面。
- 审计并优化核心内容:选出网站流量最高的10篇支柱内容,使用ChatGPT或Claude辅助,为每篇内容添加一个“关键要点”摘要,并将文中的核心数据、步骤、定义用列表或表格重新组织。
- 实施结构化数据标记:使用谷歌的Rich Results Test工具检查现有标记,并确保所有适合的内容类型(如文章、产品、FAQ、课程)都部署了正确的Schema.org标记,特别是FAQPage和HowTo,这些是AI答案的直接素材。
- 升级关键词研究流程:在Semrush或Ahrefs的关键词研究之外,增加一步:使用Perplexity AI或Google的SGE预览,手动搜索目标关键词,观察AI生成的答案摘要引用了哪些来源、偏好何种信息结构,并据此调整内容策略。
- 建立AI答案追踪机制:定期手动或使用初代监测工具(如Originality.ai的AI检测功能或有相关功能的SaaS),检查网站的核心内容是否被ChatGPT、Gemini等模型在回答相关问题时引用或总结。
- 优化“关于我们”和作者页面:AI在评估信息可信度时可能会参考网站和作者的权威背景。确保这些页面信息详实、专业,并包含明确的专业资质和联系信息。
- 谨慎处理Robots.txt:除非有明确理由,否则不要轻易在robots.txt中屏蔽主流AI爬虫。将其视为新的流量和品牌曝光入口,通过优化内容来引导其抓取行为,而非简单拒绝。
第二步:技术栈升级与标记
技术团队在robots.txt中并未屏蔽AI爬虫,而是选择积极引导。他们在网页HTML的
部分添加了针对AI的元标记,例如使用“”。同时,参考OpenAI等公司的开发者文档,为API可能调用的数据端点提供了更规范的JSON-LD格式。第三步:AI驱动的SEO工作流
内容团队的工作流被彻底改造:
第四步:创建“AI友好型”资源页面
针对“机器学习算法对比”、“自然语言处理模型发展史”等主题,团队创建了高度结构化、持续更新的专题页面。这些页面包含时间线、对比表格、模型参数清单等,极大便利了AI爬虫获取系统化知识。
数据复盘:6个月后的流量与爬虫变化
执行新策略6个月后,智研社网站的数据发生了显著变化:
这表明,优化AI可读性不仅没有损害人类用户体验,反而带来了双重提升。
方法论提炼:AI优先的SEO框架
从智研社的案例中可以提炼出一个可复用的“AI-Priority SEO框架”,包含三个层级:
这个框架的核心思想是从“为排名优化”转向“为被引用优化”,无论是在传统搜索引擎的SERP中,还是在生成式AI的答案卡片里。
行动指南:面向未来的SEO操作清单
对于希望适应这一变化的网站运营者和SEO从业者,可以立即执行以下具体行动: